
Facebook and its entire application portfolio were out for nearly six hours yesterday. I became vaguely aware when my wife asked me if the internet was out. Since I was on a Microsoft Teams call, I said no, but then noticed an issue a bit later when my wife asked again. When I saw her Instagram was down and my mom started texting me about Facebook, I reached out to some folks I know on Signal and WhatsApp, and noticed that WhatsApp was also down. At that point I realized two things: (1) that their DNS was probably down, and (2) just how large Facebook’s reach is, with over 3.5 billion people and businesses impacted around the world, prevented from accessing their social platforms, supported applications and communications.
What we know:
Facebook hosts their own Domain Name Servers. Some of their apps still use AWS services, however, for the most part Facebook has an independent infrastructure. So although my wife’s first comment, the internet is down, was caused by Facebook’s outsized presence in her communication and browsing experience, this was not a catastrophic failure.
Could such a failure be possible? The answer is “Yes”, and it has happened in the past to a degree. How is it possible? Well, similar to outages that have affected other large-scale platforms and carriers on the internet, a routing protocol that was first implemented 27 years ago was at the heart of the problem. Our old friend BGP.
For those new to the term Border Gateway Protocol (BGP), it is a protocol for moving or routing information across the internet. The entire internet as we know it relies on public and private entities using this route sharing for navigation. Your router (or your ISP provider’s router, if you are not behind your own internet router) is getting the route and then using the lowest cost route to send your traffic to the destination.
The final piece of the internet is down is the DNS server. The route tables are given in IP ranges. Each ASN has its own range of designated IPs. However, when you use an app on your phone or browser on the internet, you are not using a Public IP number. You are making calls to facebook.com, whether you are going directly to the site or using the app. So, your router is pointed to your Domain Name Server which is pointed to some sort of public registry like Cloudflare (1.1.1.1) or Google (8.8.8.8). Those registries call to find who owns, in this instance facebook.com, which then reports back from the owner’s DNS or registry an IP Number to direct your traffic from something called an “A Record”.
Here is a quick diagram to show the flow:
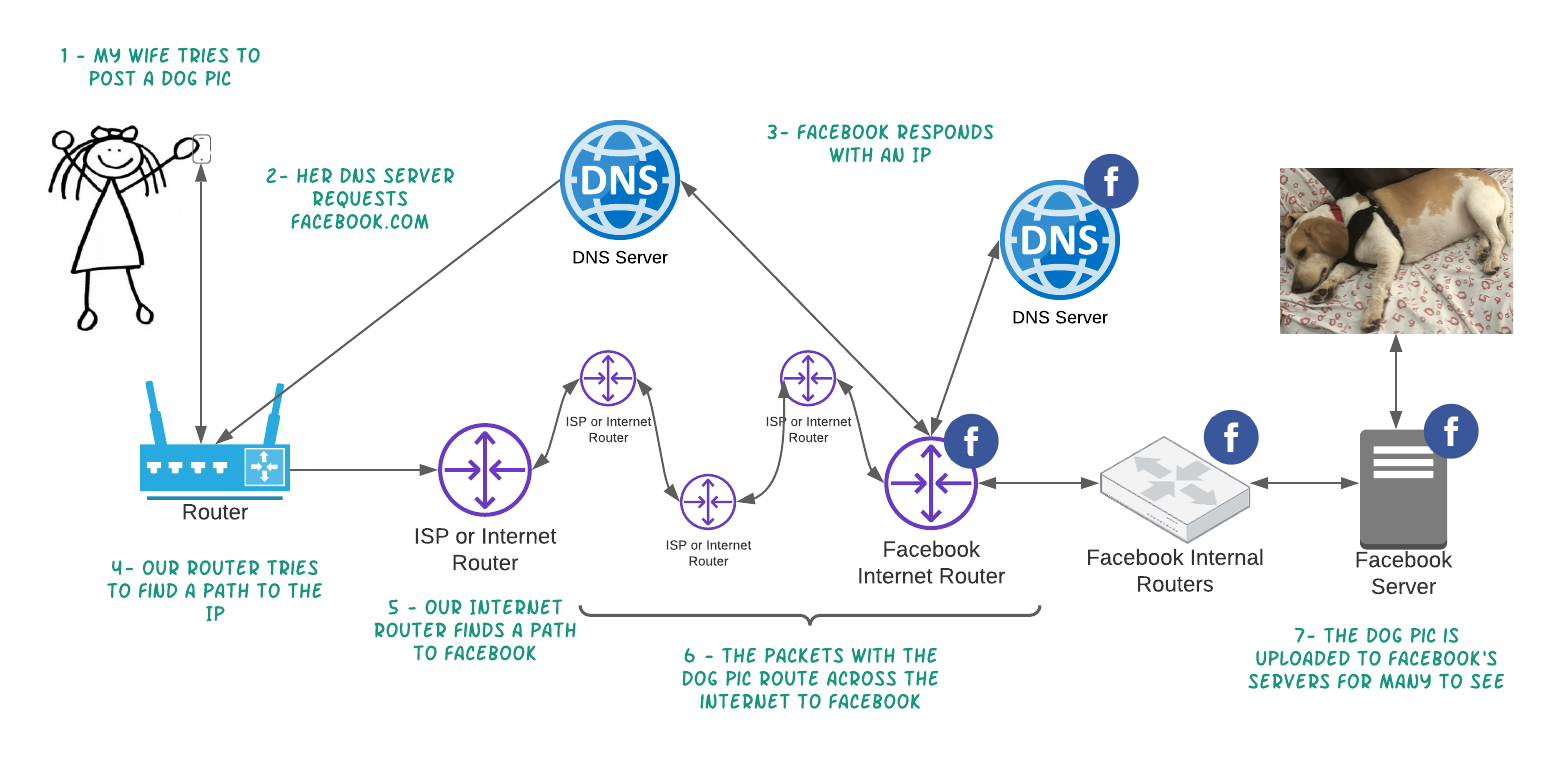
As you can see, if Facebook’s internet routers are not working, you cannot post the adorable dog pic. And that is what we know happened, which Cloudflare did an excellent job explaining. Cloudflare as well as other DNS servers were no longer getting routes to Facebook or DNS requests. We know it wasn’t just DNS Servers because a) internet router was not sharing its IPs to its neighbors and b) AWS support DNS never went down.
Lastly, this was not caused by vendor code error. Facebook, for what we publicly know, manages open hardware and software for their network infrastructure. That means their internet routers are based off Facebook propriety routers. So although this could have been caused by a bad patch or update, as well as a bad BGP configuration, the situation most likely was isolated to Facebook.
But what could have happened?
We will probably never know the full story publicly, but we do know that the Networking team at Facebook had a really bad day. There was a post on reddit from a user claiming to be a member of the team. While I am not sure on the legitimacy of the post, the scenario presented is not only plausible, but is an interesting use case to explore.
The user suggested that an automatic update pushed via GUI was not put through a router, causing a cascade event where they could not route back to the router. Without being able to route back to the router, the first step would be to use out-of-band management (a route to routers that is not controlled by the said routers that allows access in case the router malfunctions), however there was no out-of-band management to rely on, which forced the next step. Facebook had to have people in the datacenter access the machine physically. However, the team onsite did not have the right credentials and the team trying to troubleshoot had no ability to make those credentials. The identity team was locked out of systems because of the network failure (allegedly door card readers were even affected as part of the network outage). Three teams that almost never work together had to troubleshoot internally built systems with limited access, all on machines that are custom built. All of this, while there was massive internal pressure to deliver service back to their customers.
The scary part is that this story is completely plausible. As I hinted at before, there has been a couple of times where a simple BGP error has brought services of the internet down. In 2019, a BGP Optimizer along with a small configuration error, tried to make a small company in Pennsylvania the preferred path of all of Verizon. Two years before, a network engineer at Level 3 Communications accidentally updated his internal route table to the world bringing down millions of users in the US for approximately 90 minutes. These incidents happen a lot more than people care to admit, remembered always by the networking teams berated with complaints, while desperately trying to figure out what is happening, just to realize the internet is in fact down. The 2019 issue sunk over 15% of the world’s internet traffic at one point.
So, the internet can come down. But what makes this use case so interesting, especially to a cloud networking aficionado like me? Well, it highlights the five design principles I speak about all the time:
- Perform operations as code
- Make frequent, small, reversible changes
- Refine operations procedures frequently
- Anticipate failure
- Learn from all operational failures
Network teams sometimes divorce themselves from best DevOps principles. Despite most enterprise network changes being made via code or command line interface (CLI), many times they do not go through the proper build/test motions. Operational control is not watched or adhered to, as people begin to work directly on production boxes or don’t respect a change freeze, leaving you with a problem you cannot easily reverse.
This certainly happens within small companies, but sometimes the biggest perpetrators are huge enterprises, as we saw with this scenario. By working through the principles in this scenario alone, making sure the update is coded and put through a code pipeline with build/test, making sure that failures are anticipated, such as setting up out-of-band management, as well as making sure there are break fix credentials with set escalation paths, can help to avoid this kind of catastrophe. Taking the time to prepare best practices can save millions in mistakes. If all of that is looked at going forward, my wife may not need to ask again if “The Internet is Down”.
At Vandis, we work with our client’s networking teams through digital transformations whether it is building a hybrid cloud network or helping a company work towards a full DevOps model.
Next week I will discuss how we use the five design principles for our Hybrid Connectivity Quick Starts.
In the meantime, you can learn more about Vandis’ Quick Starts by calling 516-281-2200, or emailing cloud@vandis.com.